Run Spark Jobs
This document assumes you have YuniKorn and its admission-controller both installed. Please refer to get started to see how that is done.
Prepare the docker image for Spark
To run Spark on Kubernetes, you'll need the Spark docker images. You can 1) use the docker images provided by the YuniKorn team, or 2) build one from scratch. If you want to build your own Spark docker image, you can
- Download a Spark version that has Kubernetes support, URL: https://github.com/apache/spark
- Build spark with Kubernetes support:
mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.4 -Phive -Pkubernetes -Phive-thriftserver -DskipTests package
Create a namespace for Spark jobs
Create a namespace:
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Namespace
metadata:
name: spark-test
EOF
Create service account and cluster role bindings under spark-test namespace:
cat <<EOF | kubectl apply -n spark-test -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: spark
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: spark-cluster-role
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list", "create", "delete"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "create", "delete"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: spark-cluster-role-binding
subjects:
- kind: ServiceAccount
name: spark
roleRef:
kind: ClusterRole
name: spark-cluster-role
apiGroup: rbac.authorization.k8s.io
EOF
Do NOT use ClusterRole and ClusterRoleBinding to run Spark jobs in production, please configure a more fine-grained
security context for running Spark jobs. See more about how to configure proper RBAC rules here.
Submit a Spark job
If this is running from local machine, you will need to start the proxy in order to talk to the api-server.
kubectl proxy
Run a simple SparkPi job (this assumes that the Spark binaries are installed to /usr/local directory).
export SPARK_HOME=/usr/local/spark-2.4.4-bin-hadoop2.7/
${SPARK_HOME}/bin/spark-submit --master k8s://http://localhost:8001 --deploy-mode cluster --name spark-pi \
--master k8s://http://localhost:8001 --deploy-mode cluster --name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.namespace=spark-test \
--conf spark.kubernetes.executor.request.cores=1 \
--conf spark.kubernetes.container.image=apache/yunikorn:spark-2.4.4 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.4.jar
You'll see Spark driver and executors been created on Kubernetes:
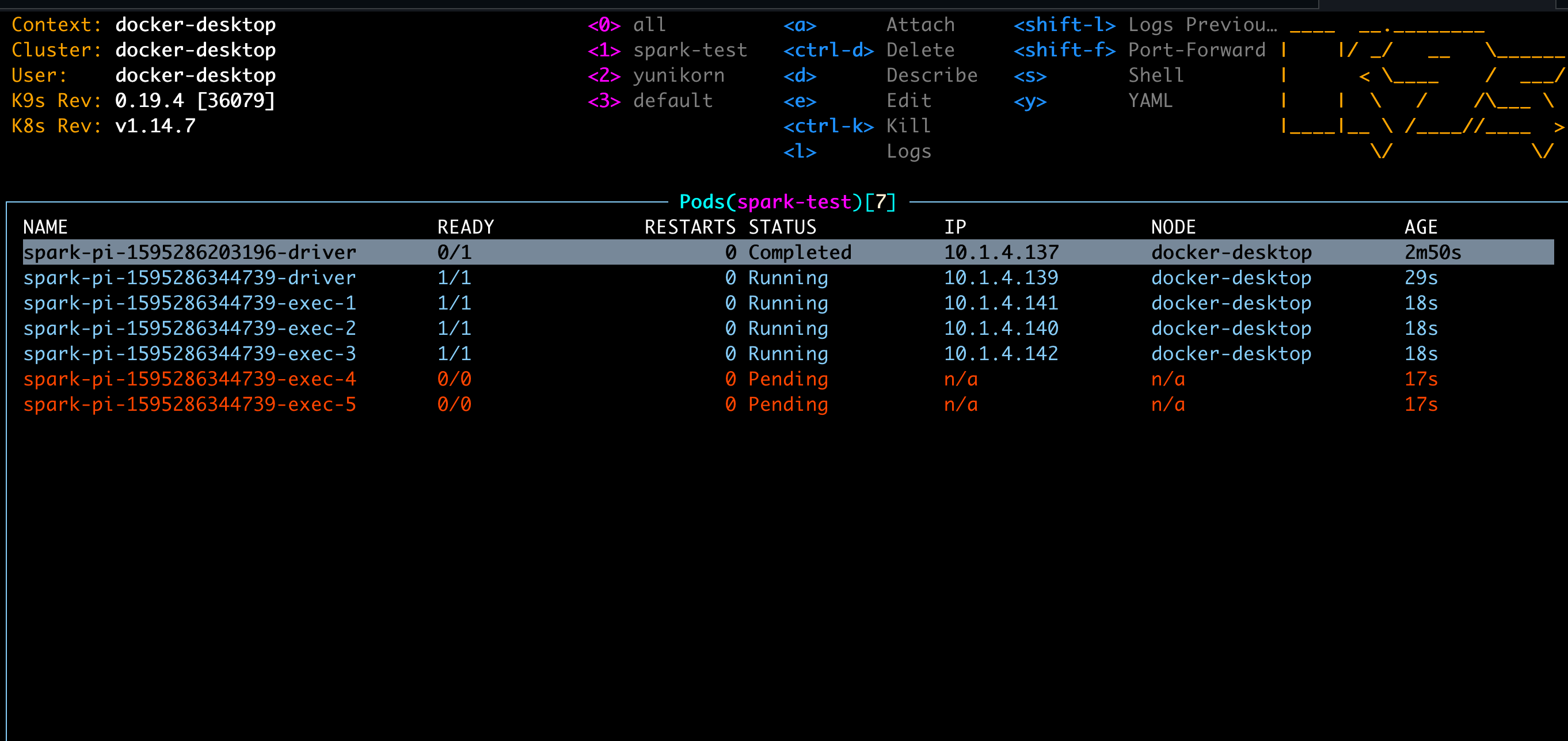
You can also view the job info from YuniKorn UI. If you do not know how to access the YuniKorn UI, please read the document here.
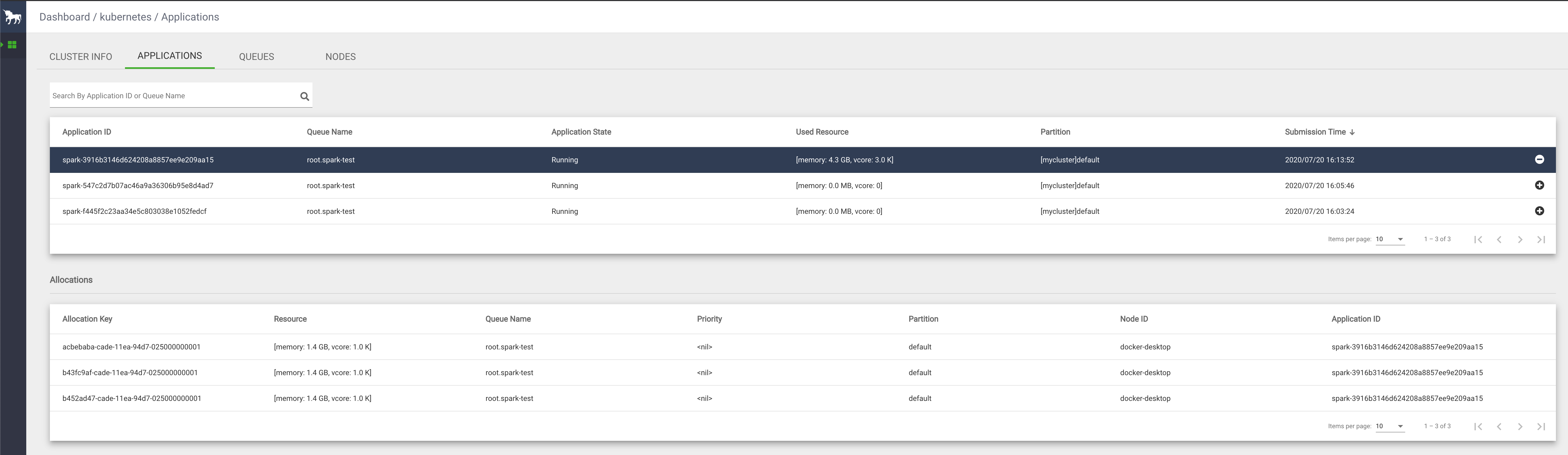
What happens behind the scenes?
When the Spark job is submitted to the cluster, the job is submitted to spark-test namespace. The Spark driver pod will
be firstly created under this namespace. Since this cluster has YuniKorn admission-controller enabled, when the driver pod
get created, the admission-controller mutates the pod's spec and injects schedulerName=yunikorn, by doing this, the
default K8s scheduler will skip this pod and it will be scheduled by YuniKorn instead. See how this is done by configuring
another scheduler in Kubernetes.
The default configuration has placement rule enabled, which automatically maps the spark-test namespace to a YuniKorn
queue root.spark-test. All Spark jobs submitted to this namespace will be automatically submitted to the queue first.
To see more about how placement rule works, please see doc placement-rules. By far,
the namespace defines the security context of the pods, and the queue determines how the job and pods will be scheduled
with considering of job ordering, queue resource fairness, etc. Note, this is the simplest setup, which doesn't enforce
the queue capacities. The queue is considered as having unlimited capacity.
YuniKorn reuses the Spark application ID set in label spark-app-selector, and this job is submitted
to YuniKorn and being considered as a job. The job is scheduled and running as there is sufficient resources in the cluster.
YuniKorn allocates the driver pod to a node, binds the pod and starts all the containers. Once the driver pod gets started,
it requests for a bunch of executor pods to run its tasks. Those pods will be created in the same namespace as well and
scheduled by YuniKorn as well.